
Sitemap
A list of all the posts and pages found on the site. For you robots out there is an XML version available for digesting as well.
Pages
DataWiz Ivani
About me
Posts
Data Analysis with Claude: Delegate, Verify, Trust
Published:
There is a useful video on Anthropic’s Academy channel titled “Data Analysis with AI”. — a short, practical walkthrough that introduces one idea that I think deserves a wider audience: the Delegation-Diligence Loop. The rest of this post is built around that idea, extended with a case study from my own work in automotive manufacturing analytics, and a frank assessment of who actually benefits from this approach and where the limits are.
Lessons learned from the first weeks of using Claude Code
Published:
The world is changing fast. In fact, it is changing so fast that I feel like letting it change and waiting out until something becomes a new standard and then starting to learn it. I wasn’t like this before, I am always open to new things, but man, the pace of change is so fast. But I decided that 2026 is the perfect time to jump on board and start learning, because some things have become standard. I finally stopped “waiting for the dust to settle” and dove headfirst into Claude Code.
Mastering Claude Code: 7 Levels of AI Orchestration
Published:
I’ve been very resiliant to trying coding assistance for some time now. It’s not that I am stubborn like some IT folks out there, it’s just that I’m lazy to learn (plus I don’t have much time with 3 kids and a full-time job). But, I’ve been following and reading a lot about the topic and I decided to try Claude Code! And to write a blog post about it. So, this is my take on properly using CC based on my research and testing so far (just 2 weeks in :) Here we go..
PandasAI: Doing Data Analytics with AI, locally, with Local LLMs
Published:
So I was poking around some tech guides the other day—you know how it is, one tab leads to another—and I stumbled upon a really interesting piece by Digital Archer group (old friends of mine) on using local LLMs for CSV analysis . It got me thinking about how much the “Text-to-SQL” world has dominated our conversations lately, while the “Text-to-Python” side of things is actually where a lot of the heavy lifting happens for us in daily data science workflows. It got me thinking about something we’ve all been wrestling with lately: how do we actually make AI work for data analysis without compromising on privacy or breaking the bank on API calls?
SQL Query Builders with LLMs: Lessons from Uber’s QueryGPT
Published:
SQL has always been the quiet tax on data work. Nobody talks about it in strategy decks, but everyone feels it. Writing queries isn’t hard in theory—it’s the constant context-switching that hurts. Which schema was that in? Which version of the table is “the right one”? Why does this column exist twice with two different names?
Data Pipeline Patterns You’ll Actually See in the Real World
Published:
If you’ve spent any time in data engineering, you’ve probably realized one thing pretty quickly: not every pipeline starts with Kafka and ends in a shiny warehouse dashboard.
The “Agentic” Shift: Moving Beyond Copy-Paste Analytics
Published:
We are entering the age of Agentic Analytics. As I’ve recently written in my previous 2 posts, with the introduction of the Model Context Protocol (MCP), we’ve moved from “chatting about data” to “deploying agents into our models.” Imagine an AI that doesn’t just suggest a formula, but actually opens your .pbix file, creates your measures, organizes your folders, hides your technical keys, and writes your documentation—all while you watch.
Power BI + MCP Tutorial: AI-Powered Report Development without Data Leaks and Additional Cost
Published:
In the last post I promised a tutorial on how to set up PowerBI connection with LLMs using MCP server. This page provides a step-by-step guide on how to use the Model Context Protocol (MCP) to connect Power BI to AI models for development while maintaining data privacy.
The New Era of Analytics: What MCP Servers Actually Mean for Analytics
Published:
Lately, it feels like we can’t talk about data without AI taking center stage. For Power BI developers, we’re at a turning point—one where AI can actually build your measures, set up relationships, and do real development work. Not by you copying DAX code into your model, but by AI directly modifying your semantic model while you watch.
CI/CD Implementation for Power BI Dashboards: From Fabric Pipelines to Code-Based Deployment
Published:
Power BI dashboards rarely start complex. A dataset here, a couple of visuals there, maybe a slicer or two. But give it a few weeks and new measures, refreshed logic, stakeholder tweaks, performance tuning, etc, and suddenly that “simple report” is business-critical.
How I Prepared for Databricks Certification (And You Can Too)
Published:
I’ll be honest, I’ve always been a bit of a Databricks fanboy. Their approach to solving data problems is just elegant. The way they’ve pushed the lakehouse architecture forward, their genuinely thoughtful implementation of AI features, the speed of their platform, it all just clicks. So when my company asked me to get certified (quotas, you know how it goes), I was actually excited about it.
Business Intelligence Tools in 2026: Enterprise vs. Open-Source
Published:
Business Intelligence (BI) tools have become mission-critical for data-driven organizations. They enable analysts and decision-makers to transform raw data into actionable insights via dashboards, reports, and visual storytelling. The landscape spans from commercial platforms widely adopted in enterprises to open-source engines popular in technical environments. But in 2026, the Business Intelligence (BI) landscape is no longer just about “making charts.” It is a battle between ecosystem locked-in giants and the rising tide of open-source flexibility. Whether you are a startup founder in Berlin or a data head at a Fortune 500 in New York, choosing the right tool determines how quickly your data turns into a competitive advantage. Let’s take a dive into most used BI tools. Check out this cool interactive webpage that I created for this purpose
DuckDB - Analytics for not-so-big data with DuckDB
Published:
In analytics engineering, tooling discussions are often presented as an either-or choice: use a transactional database like Postgres, or go all-in on a distributed engine like Spark. In practice, though, a huge share of analytical work lives somewhere in the middle. The data easily fits on a laptop or a single VM, but the queries themselves are anything but trivial—wide tables, joins across multiple fact datasets, window functions, and time-based aggregations are the norm.
The Lost Art of Testing Code in the Age of LLMs and Vibe-Coding
Published:
Santiago Valdarrama recently called out a trend many of us have felt firsthand: serious testing is quietly slipping out of software development. As he noted, we’re in an age of impressive demos, where slick presentations often matter more than whether the code is actually solid. This shows up especially when working with Large Language Models (LLMs) or doing what’s commonly called “vibe-coding”—an exploratory, trial-and-error style of writing code.
Effective Data Management in the AI World
Published:
AI is rapidly transforming industries, but at its core lies a critical foundation: data. The quality, organization, and governance of this data directly impact the success and reliability of AI models. This blog post explores what I know and what I’ve learned about the essentials of data management and its integration with AI, from fundamental concepts to practical principles and crucial considerations around security and privacy.
I Always Forget Git Commands, so I Made This Cheat Sheet for Data Science Collaboration
Published:
As a data scientist who is supposed to be working closely with developers, I constantly find myself forgetting Git commands, especially when switching between feature branches, stashing changes, or pushing to remotes. While Git is integrated into VSCode and offers a visual module for staging, committing, and syncing, I still prefer the command line. It gives me more control and a clearer understanding of what’s happening under the hood.
Level Up Your Data Science Workflow: Standardizing Projects with Cookiecutter and Git
Published:
I’m in the job hunting mode at the moment and one thing has become crystal clear: presenting a portfolio of projects in a clean, professional, and industry-standard format is crucial. My own journey of wrangling personal projects – juggling data, code, notebooks, models, and results – highlighted the need for better organization and reproducibility. How do you transform scattered scripts and notebooks into something easily understandable and verifiable by potential employers or collaborators? The answer lies in standardized project structures and robust version control.
A/B testing - principles and practicalities on how to setup the experiment
Published:
One of the most consistently expected skills for a Data Scientist today is A/B testing, often referred to as split testing. While it’s sometimes described as a simple optimization technique, in practice it’s much closer to applied science where you have to translate vague business questions into testable hypotheses, design robust experiments, and eventually, turn results into production-ready decisions.
Neural Network Force Fields for Molecular Dynamics Simulations: A Comprehensive Review
Published:
In recent years, there has been a surge in research in classical Molecular Dynamics and force-field parameterization using advanced machine learning like Neural Networks. Since this has been the topic of my PhD work, I wanted to explore the field and try to summirize recent advancing in this field. For this I wanted to test Gemini Research feature. Thus, this post is written by Gemini, and the results are very interesting.
From Molecules to Manufacturing: Understanding Storage Protocols and Modern Data Architecture
Published:
In today’s data-driven world, choosing the right storage protocol and architecture is crucial for performance, scalability, and cost efficiency. Over the years, I’ve worked with various storage systems—from NoSQL databases during my PhD to CRM systems, data warehouses, and data lakes in manufacturing. In this post, I’ll break down key storage protocols (NFS, SMB, S3) and explain the differences between data warehouses, data lakes, and the emerging data lakehouse paradigm.
Automating Insight: Bash Scripting, Command-Line Power Tools, and Data Querying
Published:
Behind every robust data pipeline or analytics project lies a powerful foundation of automation and efficient data handling. While high-level tools like SQL engines and data visualization platforms get much of the spotlight, it’s often the low-level tools—like Bash scripts, rsync, find, and others—that keep the data world running smoothly.
Beyond the SQL Basics - Mastering Advanced SQL Constructs
Published:
For data scientists and analysts, basic SQL queries are just the starting point. To truly unlock the power of databases and perform complex analyses, you need to delve into advanced constructs. This blog post explores five essential techniques: Subqueries, Common Table Expressions (CTEs), Views, Temporary Tables, and Create Table As Select (CTAS). These tools enable you to write more efficient, readable, and powerful SQL code.
Data Pipelines basics - the backbone of data apps
Published:
Data is everywhere, like a river flowing into a city. But raw data, like river water, isn’t always ready to use. We need to clean it, process it, and get it where it needs to go so it can be helpful. That’s why data pipelines are important.
Building a Siamese CNN for Fingerprint Recognition: A Journey from Concept to Implementation
Published:
The idea for this project stemmed from a collaboration with my friend Jovan on his Bachelor’s thesis. His concept was to use a Siamese Convolutional Neural Network (Siamese CNN) for fingerprint recognition, structured as follows: This blog outlines how we implemented this in Python & Keras, while dealing with dataset augmentation, Siamese architecture, and model validation. You can explore the project’s Git repo and Jupyter Notebooks.
An easy to implement AI Voice and Video Agents with Livekit: A Straightforward Approach
Published:
In this blog post, we will discuss the implementation of AI-powered voice and video agents using the Livekit platform. Our experience demonstrates that setting up these agents is a straightforward process, especially with the comprehensive documentation and tutorials available on the Livekit website. We have successfully implemented two versions of these agents: one focused solely on voice interaction and another that incorporates both voice and visual assistance.
My Dive into the Sepsis Challenge: Can Data Help Us Fight Back?
Published:
Sepsis. The word itself carries a weight of urgency. Learning that this condition, recognized as a global health priority by the World Health Assembly, is essentially our body’s own defense system going haywire in response to an infection – leading to potential widespread damage and even death [1] – really struck a chord with me. Millions affected globally each year, and the stark reality that every hour of delayed treatment increases mortality risk [2]… it’s a problem screaming for solutions.
Crafting a Standout Data Analyst Portfolio
Published:
A well-constructed portfolio is your golden ticket to showcasing your data analysis skills and landing your dream job. It serves as a window into your expertise, showing potential employers not just what you’ve done but how you think, solve problems, and communicate results. Let’s break down the essential elements of a standout data analyst portfolio and explore how to build one that truly stands out.
Analyzing Manufacturing Data - Cpk and Six Sigma
Published:
I’ve been working in Automotive manufacturing for more then a year now and there is one concept that is holy grail in this industry, and that is Six Sigma. It’s a methodology for achieving near-perfect quality in manufacturing. But how can you could leverage Six Sigma tools right from your Python environment? That’s where the manufacturing package comes in.
Anomaly Detection in HTTP Requests: A Machine Learning Approach
Published:
A while back, I was given an interesting assignment: build a model to detect anomalous HTTP requests. The goal was to identify malicious web traffic by analyzing patterns in normal and anomalous requests. This led me to explore the CSIC 2010 dataset, a well-known benchmark for HTTP anomaly detection.
SQL - The most used tool among Data Scientist and Analysts
Published:
In the world of data analysis, SQL (Structured Query Language) is the fundamental rock. It’s the language that allows you to communicate with databases, extracting, manipulating, and analyzing data with precision. Whether you’re a seasoned analyst or just starting your journey, a solid grasp of SQL is essential for uncovering meaningful patterns and driving data-informed decisions. This blog post will cover the fundamental concepts of SQL, basic query structures, and the software tools that empower data analysts. But first let’s answer what is a database and what are two main categories of databases.
Mastering the Art of Data Cleaning
Published:
As data analyst, people often ask me where do I spend most of my work time, besides scrolling through the internet. When people think about data analysis, they often imagine building predictive models or creating dazzling visualizations. But beneath the surface of every successful data project lies an essential yet often underestimated step: data cleaning. This critical process lays the foundation for trustworthy insights, making it one of the most valuable skills for any data professional.
Becoming a Data Scientist in 2024: Roadmap
Published:
As the data landscape continues to evolve in 2024, becoming a data scientist requires a multi-faceted approach, encompassing coding, mathematical proficiency, data analysis, and machine learning. This guide outlines a comprehensive roadmap to becoming a proficient data scientist, integrating essential skills and modern practices such as working with Large Language Models (LLMs) and prompt engineering.
First Principles Thinking in everyday life
Published:
Hey there!
portfolio
Fingerprint Verification System Using a Siamese Neural Network in Keras
Published:
CNN Siamese model for fingerprint recognition using Python & Keras, while dealing with dataset augmentation, Siamese architecture, and model validation1
SQL Data Cleaning and Preparation for Analysis
Published:
Transforming Raw Coffee Survey Data: A PostgreSQL Cleaning Journey 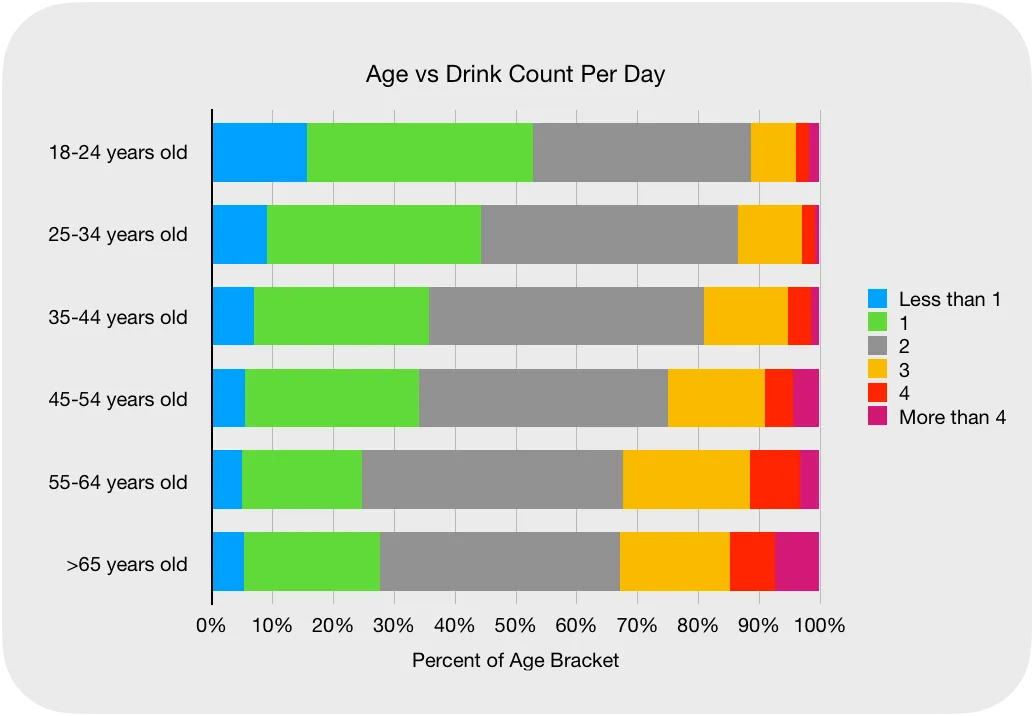
Anomaly Detection in HTTP Requests: From Supervised to Unsupervised Learning
Published:
Anomaly detection Supersied and Unsupervised Machine Learning to detect malicious HTTP requests by parsing raw traffic logs, engineering TF-IDF features, and achieving 79% accuracy—highlighting the importance of preprocessing in cybersecurity ML tasks1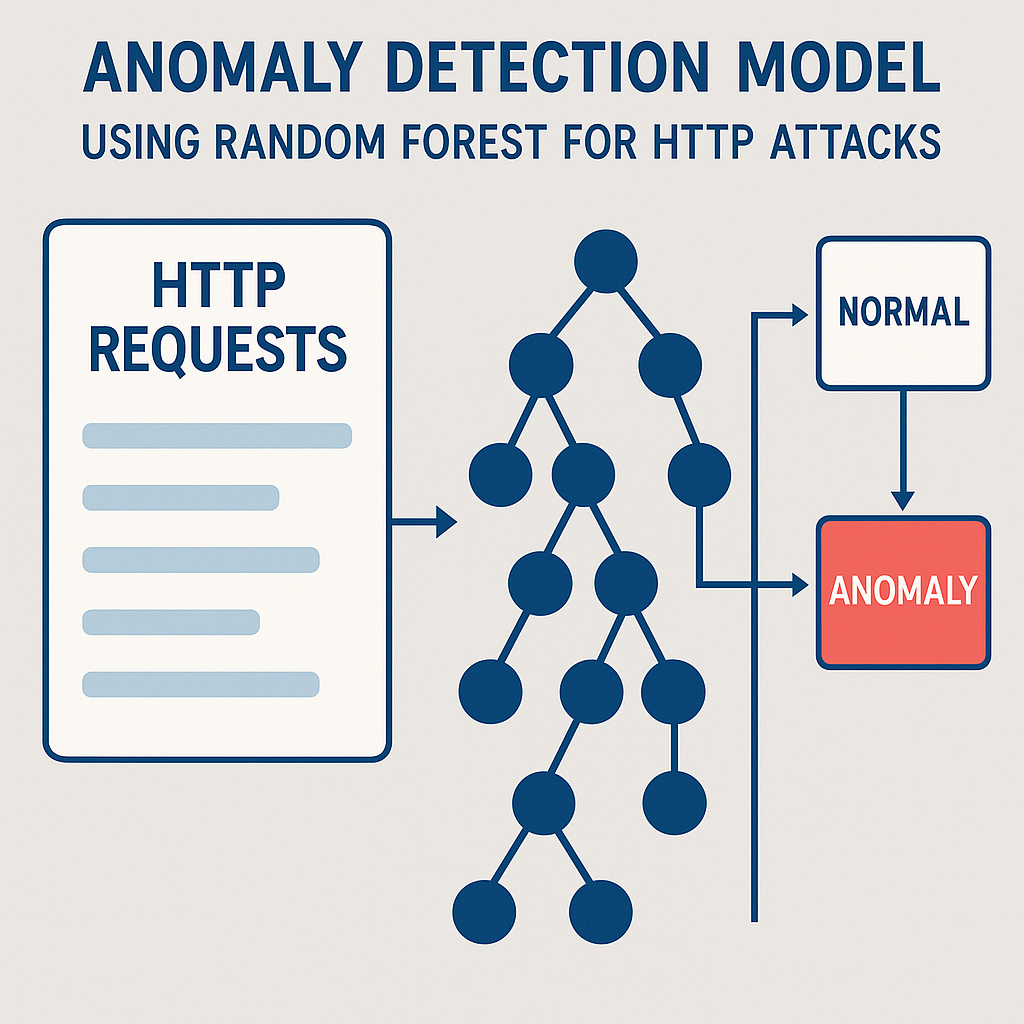
Comparative analysis of most used BI tools
Published:
We looked at the most commonly used BI tools, analyzed their pros/cons and usage world-wide and per sectors. Click on the link in the post to take you to the webpage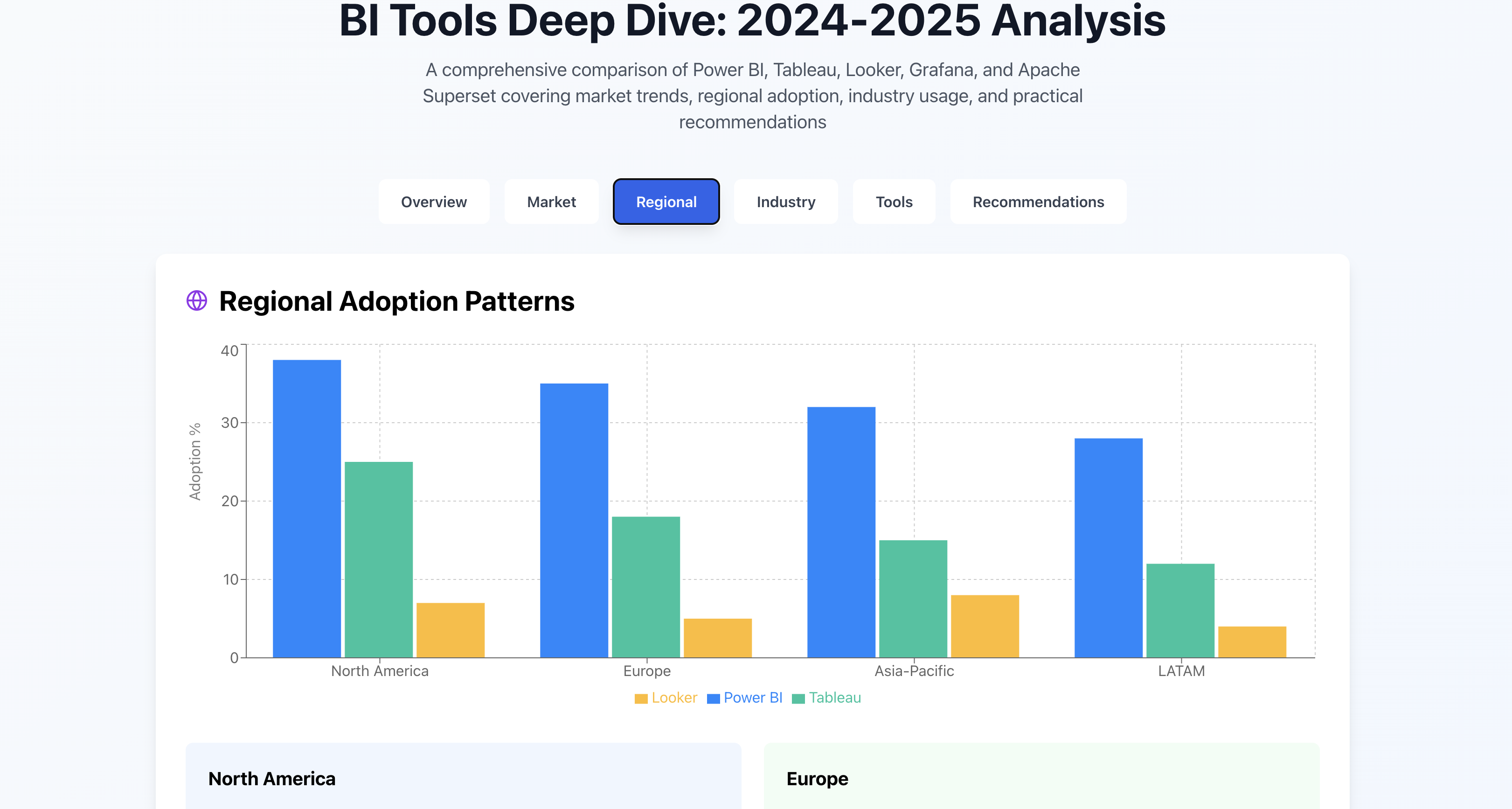
publications
Paper Title Number 1
Published in Journal 1, 2009
This paper is about the number 1. The number 2 is left for future work.
Recommended citation: Your Name, You. (2009). "Paper Title Number 1." Journal 1. 1(1). http://academicpages.github.io/files/paper1.pdf
Paper Title Number 2
Published in Journal 1, 2010
This paper is about the number 2. The number 3 is left for future work.
Recommended citation: Your Name, You. (2010). "Paper Title Number 2." Journal 1. 1(2). http://academicpages.github.io/files/paper2.pdf
Paper Title Number 3
Published in Journal 1, 2015
This paper is about the number 3. The number 4 is left for future work.
Recommended citation: Your Name, You. (2015). "Paper Title Number 3." Journal 1. 1(3). http://academicpages.github.io/files/paper3.pdf
Paper Title Number 4
Published in GitHub Journal of Bugs, 2024
This paper is about fixing template issue #693.
Recommended citation: Your Name, You. (2024). "Paper Title Number 3." GitHub Journal of Bugs. 1(3). http://academicpages.github.io/files/paper3.pdf
talks
Talk 1 on Relevant Topic in Your Field
Published:
This is a description of your talk, which is a markdown files that can be all markdown-ified like any other post. Yay markdown!
Conference Proceeding talk 3 on Relevant Topic in Your Field
Published:
This is a description of your conference proceedings talk, note the different field in type. You can put anything in this field.
teaching
Teaching experience 1
Undergraduate course, University 1, Department, 2014
This is a description of a teaching experience. You can use markdown like any other post.
Teaching experience 2
Workshop, University 1, Department, 2015
This is a description of a teaching experience. You can use markdown like any other post.